MCP security operativa + protección de datos de IA en pipelines agentic
Si conectas LLMs a herramientas vía MCP y tu modelo de seguridad se queda en “poner OAuth”, te estás cubriendo solo a medias. El riesgo de verdad aparece al combinar delegación OAuth, identidad de workload y circulación de datos sensibles entre tools y respuestas del agente.
Tesis: sin un control coordinado de autorización, identidad y data plane, MCP amplía la superficie de ataque más rápido de lo que tu observabilidad puede absorber.
Qué cambia en MCP frente a integraciones API tradicionales
La diferencia no está en un ataque aislado, sino en cómo se encadenan varios.
- Tool poisoning en descripciones, schemas o outputs.
- Tool shadowing entre dominios de confianza distintos.
- Confused deputy en proxies OAuth mal diseñados.
- Exfiltración por canales legítimos (correo, búsqueda, ticketing, etc.).
En la práctica, una tool de baja confianza contamina el contexto, otra de alta confianza ejecuta, y en logs todo puede parecer normal si no controlas egress ni correlacionas identidad de extremo a extremo.
Arquitectura mínima para producción
Piénsalo como tres planos que se apoyan mutuamente.
1) Plano de control (AuthN/AuthZ)
- Consentimiento por
client_iden el proxy MCP. - Matching exacto de
redirect_uri. stateúnico y de vida corta.- PKCE S256 en clientes públicos.
- Sin token passthrough; tokens con audiencia y scopes mínimos por recurso.
2) Plano de identidad (workload)
- Identidad efímera de servicio con SPIFFE/SPIRE.
- mTLS para tráfico este-oeste.
- Separación por trust domain cuando cambian el riesgo o los requisitos regulatorios.
3) Plano de datos (IA)
- Clasificación de datos en input y output de tools.
- Validación y sanitización estricta de parámetros y respuestas.
- Egress control con allowlists y detección de patrones de exfil.
- Trazabilidad de delegación: usuario → agente → tool → API.

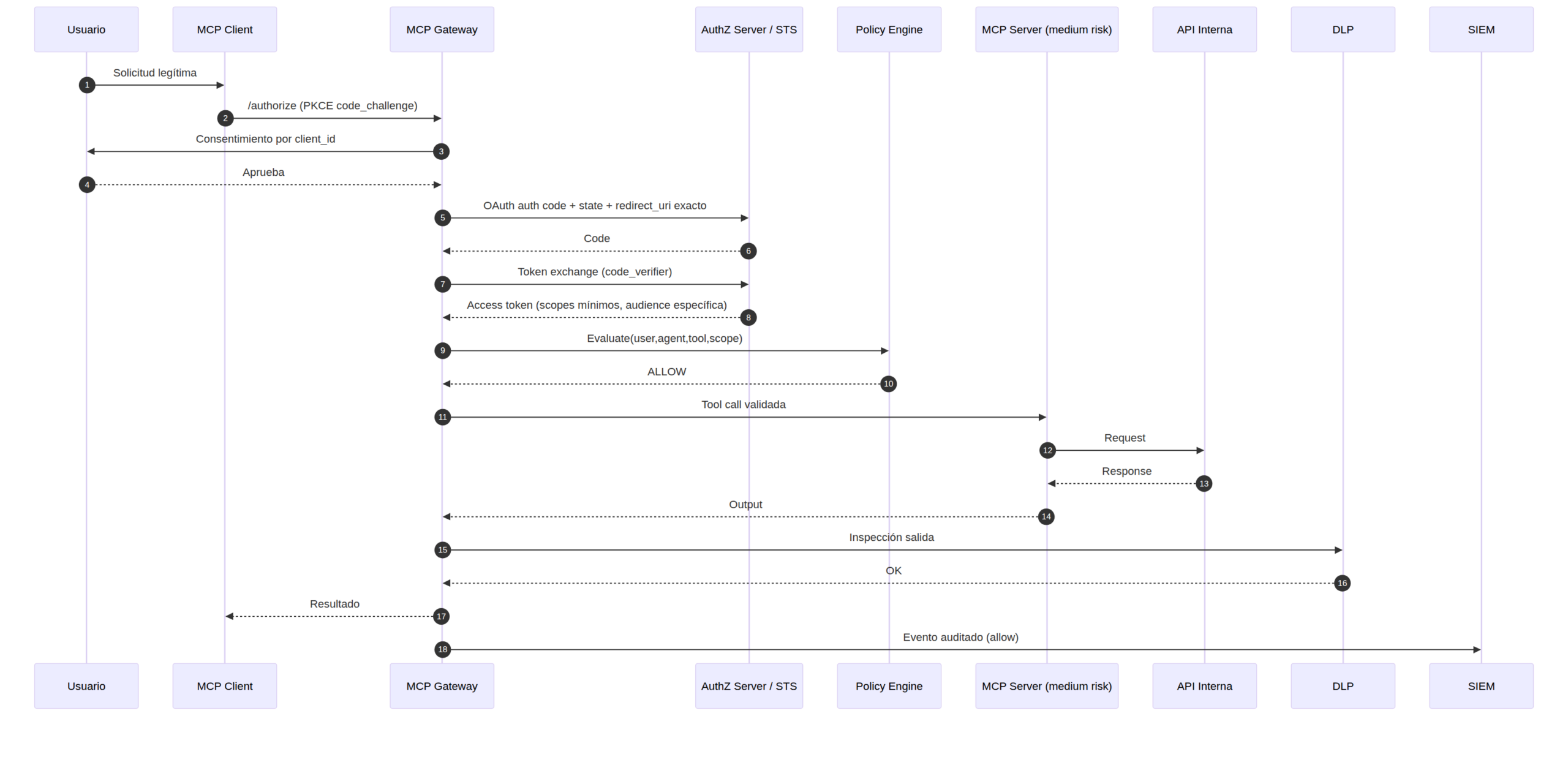
Secuencia ALLOW: operación legítima y auditable
- El cliente inicia autorización con PKCE.
- El proxy MCP exige consentimiento propio por cliente.
- Se valida de forma estricta
redirect_uriystate. - El STS emite un token delegado con scopes mínimos y audiencia específica.
- El policy engine evalúa contexto y autoriza.
- El DLP inspecciona la salida antes de devolver respuesta.
- El SIEM registra el evento correlado.
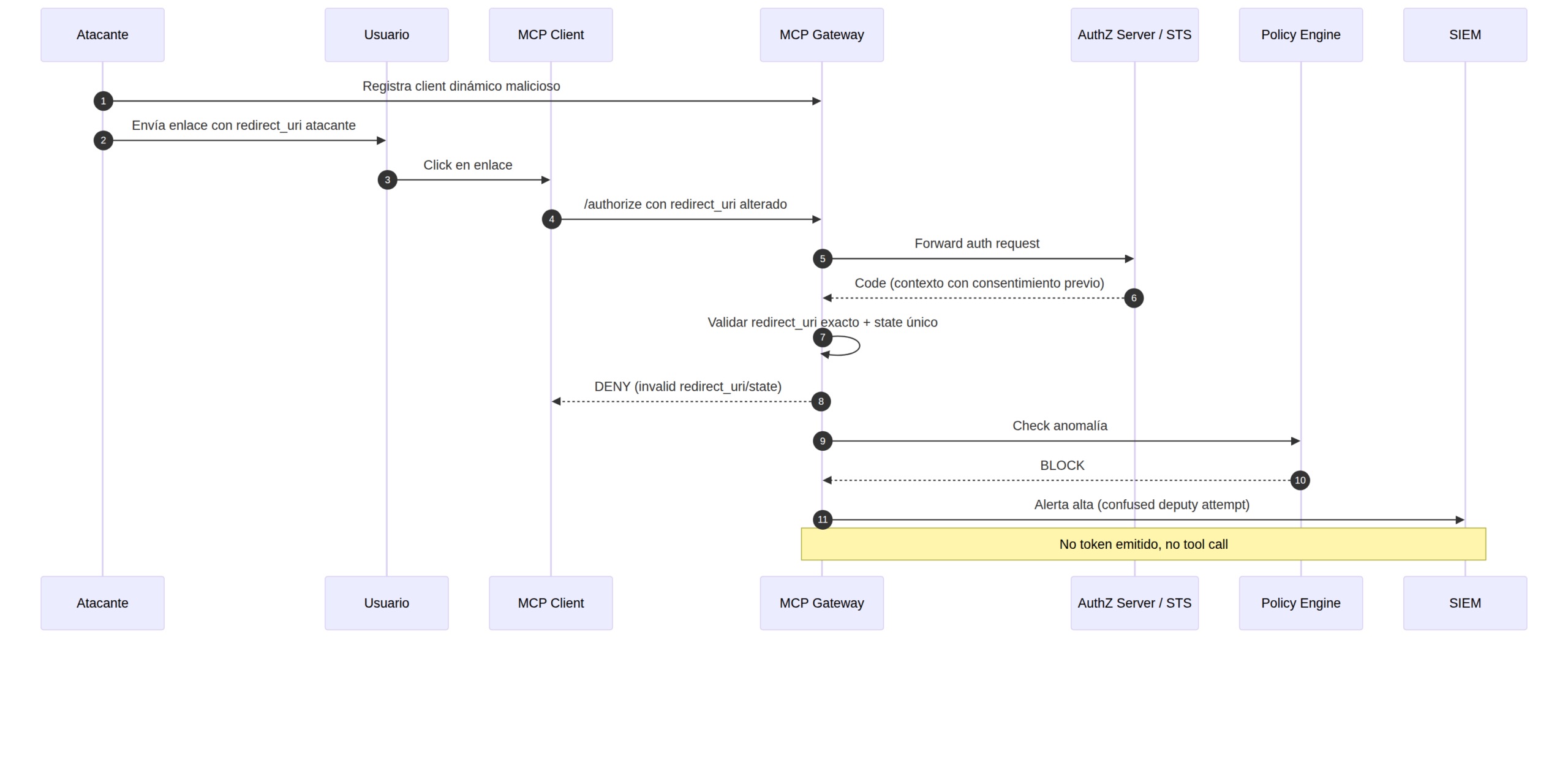
Secuencia DENY: intento de abuso bloqueado
- Un atacante intenta cliente dinámico y
redirect_uribajo su control. - Aprovecha contexto de consentimiento previo.
- El proxy detecta mismatch o
stateinválido/reutilizado. - Se bloquea la emisión/intercambio de token.
- Se genera una alerta de alta severidad con el contexto del intento.
Patrones de implementación con trade-offs reales
A) On-Behalf-Of (token exchange)
Es útil cuando necesitas evidencia criptográfica de que el agente actúa en nombre del usuario. Reduce ambigüedad sobre quién hizo qué y mejora la auditoría, a costa de más complejidad en STS y gestión de claims.
B) Gateway fuerte + autenticación de plataforma al runtime
Ejemplo típico: gateway autenticado por SigV4/mTLS hacia runtime, con claims validados en borde. Recorta llamadas directas no autorizadas, pero exige blindar ese borde; un header sin firma no equivale a identidad.
C) Segmentación de servidores MCP por dominio de confianza
No mezcles tools de PII/finanzas con tools de bajo riesgo en el mismo dominio. Bajas riesgo de shadowing y de escalada lateral, con el coste de una operación más compleja.
Mapa de riesgo de skills/tools
Bajo: calendar-readonly
- Caso: lectura de disponibilidad.
- Inputs: rango temporal y zona horaria.
- Outputs: slots ocupados/libres.
- Guardrails: scope read-only.
Medio: crm-update-ticket
- Caso: transición de estado de incidencias.
- Inputs:
ticket_id,status,note. - Outputs: confirmación de transición.
- Guardrails: allowlist de transiciones y ownership.
Alto: payments-transfer
- Caso: transferencia monetaria.
- Inputs: origen, destino, importe, motivo.
- Outputs: identificador de operación.
- Guardrails: HITL, dual control, límites por rol y antifraude.
---
name: payments-transfer
description: Ejecuta transferencias con validaciones antifraude y aprobación humana.
---
# Inputs
- from_account (string)
- to_account (string)
- amount (number)
- currency (string)
# Guardrails
- additionalProperties: false
- amount <= límite dinámico por rol
- require_human_approval: trueQué nos dicen los papers (arXiv y similares)
Si bajas a evidencia empírica, el patrón es consistente: el riesgo en agentes con tools no viene solo del modelo, viene de la composición entre prompt, tool metadata, ejecución y salida.
Hallazgos que sí cambian decisiones de arquitectura
- El riesgo no es teórico. En MCP Safety Audit se documentan rutas de explotación que acaban en ejecución maliciosa, toma de control remota y robo de credenciales en workflows MCP mal protegidos.
- Escala del ecosistema, escala de exposición. En MCP at First Glance (1.899 servidores MCP analizados), los autores reportan 7,2% con vulnerabilidades generales y 5,5% con señales de tool poisoning.
- Supply chain MCP real. En Toward Understanding Security Issues in the MCP Ecosystem se analiza un corpus de 67.057 servidores de registros públicos y se describen vectores de secuestro/hijacking en una fracción relevante del ecosistema.
- Las defensas frágiles se rompen. Adaptive Attacks Break Defenses Against Indirect Prompt Injection consigue bypassear ocho defensas y mantiene tasas de éxito por encima del 50% en su evaluación.
- Hay defensas prometedoras si impones estructura. Task Shield reporta 2,07% de attack success rate con 69,79% de utilidad en AgentDojo (GPT-4o), e IPIGuard muestra mejoras al separar planificación de ejecución con grafo de dependencias de tools.
- El problema no es solo MCP. Agent Security Bench (ASB) mide seguridad de agentes LLM en múltiples escenarios y observa picos de éxito de ataque de hasta 84,3%, lo que refuerza la necesidad de controles por capas.
Traducción práctica: de papers a controles operables
- Planificación separada de ejecución. Congela el plan de tools antes de ingerir datos no confiables y exige justificación explícita para cada salto de tool.
- Verificación antes de commit. Para acciones sensibles, aplica un paso de verificación independiente (policy + contexto + identidad) antes de ejecutar.
- Tool contracts estrictos. Schemas cerrados, límites de parámetros y chequeos semánticos de salida para cortar tool poisoning y desvíos de flujo.
- Aislamiento por dominio de riesgo. No mezcles tools de lectura abierta con tools de escritura crítica en el mismo trust domain ni en el mismo runtime de ejecución.
- Evaluación continua con ataques adaptativos. Si tu benchmark solo mide ataques estáticos, te estás engañando. Mete red-team adaptativo en CI/CD de agentes.
Checklist operativo de despliegue
Antes de exponer MCP remoto
- TLS obligatorio y binding de host/interface restringido.
- OAuth con PKCE,
staterobusto y rotación de secretos. redirect_uriexacto, sin wildcards.- Rechazo explícito de token passthrough.
Antes de habilitar tools sensibles
- Schema JSON estricto (
additionalProperties:false). - Validación de input con allowlists y patrones.
- Sanitización de output para evitar inyección en cadena.
- Aprobación humana en acciones destructivas o financieras.
Operación diaria
- Métricas de egress por tool y tenant.
- Alertas por deriva de scopes/permisos.
- Pinning/hash de descriptores de tools y alertas de cambio.
- Auditoría correlada: request → decisión de policy → tool call → respuesta.
Referencias
- OWASP MCP Security Cheat Sheet — checklist técnico base para endurecer hosts, tools y flujos MCP.
- MCP Security Best Practices — guía oficial del protocolo para controles mínimos y límites de confianza.
- Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions — panorama del ecosistema MCP y taxonomía de amenazas por ciclo de vida.
- MCP Safety Audit: LLMs with the Model Context Protocol Allow Major Security Exploits — demuestra rutas de ataque prácticas y propone auditoría preventiva de servidores MCP.
- Model Context Protocol (MCP) at First Glance: Studying the Security and Maintainability of MCP Servers — estudio a gran escala de 1.899 servidores MCP con métricas de seguridad/mantenibilidad.
- Toward Understanding Security Issues in the Model Context Protocol Ecosystem — análisis de riesgos de host/registry/server sobre un corpus masivo de servidores públicos.
- Agent Security Bench (ASB) — benchmark amplio de ataques/defensas en agentes LLM con foco en trade-off utilidad-seguridad.
- Adaptive Attacks Break Defenses Against Indirect Prompt Injection Attacks on LLM Agents — evidencia de que defensas estáticas fallan frente a atacantes adaptativos.
- The Task Shield — defensa basada en alineación de tarea para reducir IPI sin destruir utilidad operativa.
- IPIGuard — enfoque de grafo de dependencias de tools para contener invocaciones inducidas por inyección indirecta.
- Not What You’ve Signed Up For (Indirect Prompt Injection) — trabajo seminal sobre inyección indirecta en apps integradas con LLM.
- RFC 7636 (PKCE) — base para proteger authorization code flow en clientes públicos.
- RFC 9700 (OAuth 2.0 Security BCP) — prácticas actuales para endurecer OAuth y reducir ataques de delegación.
- CISA: Securing AI Data — marco operativo para protección de datos de IA en pipelines reales.
- SPIFFE Concepts — modelo de identidad workload para mTLS y segmentación de confianza.
- SPIFFE-ID Standard — especificación de identidad verificable máquina-a-máquina.
Criterio de aceptación en MCP: no basta con que “funcione”. Tiene que funcionar, poder auditarse y fallar en modo seguro.